
“There is little… value in demonstrating that an impotent man can be made to say that he is no longer impotent. The relevant question is not what he can say, but rather what he can do.” (Baer, Wolf, & Risley, 1968, p. 93)
Fast-Tracking Single-Case Designs
A new paper in Perspectives on Behavior Science prompts interesting questions about the methods on which we rely in behavioral research. I refer you to Byrne (2025), whose subtitle proclaims, “How to conduct a multiple baseline experiment… in under an hour.” Byrne’s interest is in the teaching of behavioral methods, specifically in giving students a good experience without need for a dedicated lab space or much specialized equipment.

I agree 100% with Byrne that it’s important for students to learn about research design — especially in an era where so many are attracted to behavior analysis, not for love of science, but rather by the lure of lucrative practice opportunities — and it’s critical to preserve our discipline’s tradition of data-driven practice. Hence it matters that all students of behavior, regardless of professional goals, have a firm understanding of how to objectively decide when behavior change really has occurred.
Unfortunately, reading about research methods is one of the dullest and least inspirational things imaginable. But seeing behavior change in real time is incredibly exciting! The venerable teaching-focused Rat Lab or Pigeon Lab, once a fixture in many academic departments, used to provide countless students with an informative experience in documenting behavior change. Many students counted it as among their most memorable experience in college. But sadly, teaching labs as we used to know them are all but extinct (Postscript 1) because they are expensive to maintain and sometimes hard to sell to animal ethics committees. Byrne explains why labs featuring planaria (aquatic flatworms) are subject to neither of those problems and are surprisingly easy to set up.
Time Warp
But I’d like to riff on a different theme suggested by Byrne’s paper: the difficulties professional researchers encounter when conducting behavioral research. I once helped with an investigation in Andy Lattal’s lab that ran for the better part of my PhD. studies. In our steady-state, single-subject design, each experimental condition consumed up to 100 or so daily sessions. Our methods reflected the principles spelled out in Sidman’s (1960) seminal Tactics of Behavioral Research, two the foundational ideas of which are that (a) you must directly observe behavior, and (b) you can’t know what’s happening in a given experimental condition without extensive behavioral measurements that show limited variability.
There is no question that those precepts support strong investigations, and I certainly don’t quibble with them on conceptual grounds. I do, however, have reservations on practical grounds, which that endless experiment I mentioned above helps to illustrate. When I started my first academic job, post-Ph.D., I compared publications with a colleague who was hired at the same time but trained in a different research area. I learned that during the time required to run the endless experiment mentioned above my colleague had conducted eight complete experiments! I quickly became aware that, within the publish-or-perish survival conditions of academia, Sidman’s methods would put me at a disadvantage.
The problem wasn’t just about promotion and tenure, of course. A completed experiment is one exemplar in a researcher’s multiple-exemplar training in how to do research and how to understand the chosen subject matter. My exemplars were trickling in at a much slower rate than my colleague’s. And because faster research = faster scientific progress, the faster you can get things done, the better.
Fast is particularly important when your research focuses on participants of the variety homo sapiens who, unlike Andy Lattal’s pigeons, aren’t captive in the lab and, annoyingly enough, are permitted to come and go as they please. In conducting human operant experiments over the years, I must have lost 40% to 50% of research volunteers to boredom and other sources of attrition – they’d sign on, work for a while, and then quit. Because the resulting data were useless, this cost me valuable time. Because research volunteers must be compensated for their efforts (even incomplete efforts), it also cost me a lot of money.

In applied research, access to client-participants is also finite — and, truly, you never know how finite. I once supervised a thesis that was conducted at a group home. It went swimmingly until my student, Cheryl Ecott (inset), and I provoked the Universe by deciding we needed just one or two more data points to polish off our very tidy experiment. On a Monday morning, then, Cheryl dutifully arrived at the group home to collect her final data, only to find that over the weekend it home had closed and the resident-participants had been dispersed to homes all over the state. Scientific mayhem ensued.
The reality is that steady-state operant methods originally were conceived with captive animal participants in mind and, despite their benefits, serious practical costs are incurred when you embrace them. To give credit where it is due, Sidman understood this and advocated for measures that tend to shorten experiments (e.g., ramping up the potency of the independent variable and clamping down on extraneous variables). These things definitely help. When I first started doing steady-state concurrent-schedules experiments with humans, maybe 15 hours of schedule exposure was required to complete a single condition. With experience, I got that down to about two hours, but even so a complete experiment might still take 20 total hours that few volunteers were willing to give me.
Nothing I say next is likely to register unless we remember that it hasn’t always been this way in behavioral research. Just for fun, flip through the articles from the early volumes of our discipline’s first journal, Journal of the Experimental Analysis of Behavior (founded 1958), and you won’t find a steady stream of Sidmanesque steady state experiments until around the dawn of the 1970s. This is a reminder that the experimental analysis of behavior, as Skinner brought it to life in his early research, tended to focus on short studies, some measured in minutes and documented using a single cumulative record. Steady-state methods were latecomers to the party, which demonstrates that there are, and indeed always have been, other ways to do research (Postscript 2).
Since Sidman came along to make our lives difficult (wink), we’ve seen the occasional instance in which someone figured out how to get an experiment done more quickly – for instance, Alan Neuringer played around with how to map out human matching-law functions in a brief video-game procedure. For the most part, however, we’ve not strayed much from what Sidman taught us (if you doubt me, check any contemporary methods textbook).
On The Madness of Crowds
But WHY not? If experiments are the building blocks of a dynamic science, and our experiments are prohibitively difficult to complete, why wouldn’t we invest thought and effort into streamlining our methods? Yes, it’s true that breaking the rules of behavioral research as they are taught today could potentially result in messiness… but we won’t know until we try out alternative approaches to see where they lead us.
Aside from being willing to nettle the behavioral gods by doing something the methods books say is verboten, the necessary starting point is to engage with some alternative method to see whether it can detect and accurately represent effects that have been well established using slower methods. One possible example: Group comparison designs. Instead of a few individuals participating for a long time, in group designs many individuals participate for a short time each. Instead of mapping behavioral functions for each individual separately, you map functions based on aggregating results from many individuals. Such methods are handy when participant time is in short supply (basically, always). Yes, yes, I know what you’ve been told about the dangers of group methods (e.g., see Sidman, plus here and here). Supposedly mixing the data from different individuals gives you a false picture of behavior – that’s the hypothetical disaster textbooks tell you about. But can you show me actual evidence of catastrophe? In other words, in the research literature, is there really a consistent pattern of group-comparison studies yielding different (and worse) results than single-case research?
If you can demonstrate this systematically, please publish a review article right away, because currently there is little objective evidence to support this purported Achilles heel of group methods. To make the needed comparison you first need to find research areas where group and single-case research both have been conducted in earnest. In two such areas – stimulus control and punishment – it turns out that much of the foundational behavioral research was conducted in group designs. And, critically, single-case research largely verifies what the group-design studies told us (check that for yourself if you don’t believe me). Alan Neuringer, mentioned above, understood this when developing his video-game procedure for demonstrating concurrent-schedules effects. Unlike in your typical matching experiment, each participant was in only one experimental condition. But when Neuringer pooled the data from several participants, the matching function looked a lot like results obtained from traditional single-subject rat experiments.
Liars and Idiots
Another place where we’ve been cautioned never to stray is into the realm of verbal-report measurement. Probably no one had more to do vilifying verbal-report measurement than Baer, Wolf, & Risley (1968), via the snarky “impotent man” observation that led off this post. Ever since, most behavior analysts have taken as given that you aren’t doing real behavioral research unless you perform direct observations of behavior. Verbal-report data, in which people say what they do, are a sin reserved for sloppy mainstream investigators (Postscript 3).
I’ve written elsewhere about the conceptual issues involved in verbal report measurement (e.g., download), and I won’t repeat myself except to say that a full-scale ban on verbal-report measurement is predicated on faulty assumptions. Contrary to what you’ve been told – that people are liars and idiots whose verbal behavior cannot be trusted — sometimes saying mirrors doing pretty well. And if saying can provide informative behavioral data, well, that often happens more quickly and easily than observing behavior in other ways. Jalie Tucker and Rudy Vuchinich demonstrated as much in a wonderful series of papers on the behavioral economics of alcohol abuse. They developed and validated a special interview method to measure, over extended periods, people’s alcohol intake and everyday environmental influences, things that would be tricky to measure through direct observation “in the wild” (e.g., good luck following alcohol abusers around to record what they drink every hour of every day). Tucker and Vuchinich showed that various (self-reported) effects of clinical importance – like help-seeking, recovery, and relapse — conform to what behavioral economic theory predicts and provide valuable treatment insights. [The method is continualy being updated and extended; see this recent report on its use in youth alcohol research).
An Example: Generalization Gradients Faster Than You Can Boil an Egg
To help make my case for the potential utility of verbal-report methods, I’d like to share with you some unpublished data, which I’ll get to momentarily. The context is the testing of gradients of stimulus generalization, and you probably know the traditional method. First you train up a discrimination. Then you conduct a series of probes in which a participant is presented with S+ and a variety of stimuli in varying degrees of similarity to it. You measure how much behavior is occasioned by the various stimuli, with the typical result being a positive correlation with how similar test stimuli are to S+. Now, compared to 100 sessions per condition, generalization testing is not the most time-consuming method, but with humans it can take 30 minutes or more (and every human researcher knows that with human participants short attention spans are a concern).
But what might happen if, instead of asking participants to show us how similar a test stimulus is to S+, we asked them to simply tell us? That could go a lot faster – the whole experiment could last a few moments, which would be lovely if the results are trustworthy. That, in fact, already has been demonstrated in a smattering of published studies that used rating-scale procedures instead of traditional generalization testing and produced effects that are quite familiar within the context of the generalization literature. Examples:
| Study | Type of stimuli |
|---|---|
| Duke, Bigelow, Lanier, & Strain (2011). Discriminative stimulus effects of tramadol in humans, Journal of Pharmacology and Experimental Therapeutics. | different doses and types of drugs |
| Rush, Kollins, & Pazzaglia (1998). Discriminative-stimulus and participant-rated effects of methylphenidate, buproprion, and triazolam in d-amphetamine-trained humans. Experimental and Clinical Psychopharmacology. | different doses and types of drugs |
| Lane, Clow, Innis, Critchfield (1998). Generalization of cross-modal equivalence classes: Operant processes as components in human category formation. Journal of the Experimental Analysis of Behavior. | tones of different pitch |
| Miller, Reed, & Critchfield (2015). Modeling the effects of melanoma education on visual detection: A gradient shift analysis. Psychological Record. | images of skin lesions showing varying degrees of melanoma symptoms |
Postscript 4 summarizes a little pilot investigation employing verbal ratings that was thrown together — literally I conceived and programmed it in a day — a while back in my lab. The study ran in an online automated course delivery system and took in the range of about 2-3 minutes for most participants to complete — that’s the entire experiment. Nevertheless, the study yielded passable generalization gradients that are consistent with what’s seen in more traditional procedures.
Getting Informative Data in the Minimum Time
In the example of Postscript 4, a fairly unsophisticated verbal-report procedure yielded results that will look familiar to any student of the stimulus generalization literature. I never got to follow up on the pilot study, but I have no doubt that with a bit of refinement such a procedure could yield even more orderly data. The point is simply that if you can get informative data using a streamlined procedure, why would you ever prefer to do something more laborious and time consuming?
This sounds like an uncontroversial assertion: With research time always in short supply, we should always want to get our data in as little time as possible. But leave it to our discipline to this make this a bone of some contention. For instance, some applied behavior analysts were outraged when Greg Hanley and colleagues introduced a very brief, interview-based functional assessment tool (in a now-infamous episode, Greg’s own mentor devoted an entire invited address at a major conference to excoriate him about this). Another example: Behavioral economic methods, such as those designed to measure delay discounting or demand curves, often rely on verbal-report measurement, and I can’t tell you how often I’ve seen peer reviewers call out those methods on principle alone, without carefully examining their empirical utility, and without considering the wealth of data demonstrating their validity. Not too long ago a rather famous behavior analyst posted a lengthy online video suggesting that such methods are entirely bankrupt and can show us nothing valuable. And yet, if you want an object lesson in some ways to validate verbal-report data, I do recommend the behavioral economics literature. Those people are neither foolish nor lazy, and they have developed bang-up methods that don’t look anything like traditional behavioral research yet somehow reveal effects that validate and extend behavior principles as the behavior analyst knows them.
If I could corner the ghosts of Baer, Wolf, and Risley in some celestial bar, I’d buy them a round and and pose this question: How would they propose collecting data on erectile dysfunction (see that quote above) in the naturalistic settings where it creates the most problems? I can’t imagine any of those distinguished gentlemen sneaking into client bedrooms to perform direct observations of sexual activity. And although mechanical measurement of relevant physiological responses is possible, that’s unlikely to be useful outside of a lab. If we want to learn about sexual activity, then, we might need to ask. This illustrates how in some contexts it is extremely important to know whether we can trust what people tell us. Under some conditions we can trust, as the timeline followback research illustrated starting about 25 years ago. Once the validity of verbal-report methods has been demonstrated under one set of conditions for one kind of behavior, then any omnibus assertion that verbal-report measurement is necessarily faulty becomes, by definition, false.

This means that decisions about what behavioral methods can be used in what circumstances are more nuanced than behavior analysis textbooks — and Baer et al. (1968) — would have you believe. But behavior analysts are a stuffy bunch when it comes to research design. Over the years, for instance, I’ve seen reviewers in behavior analysis journals heap a ton of umbrage on studies that deviate from our discipline’s methodological orthodoxy. This implies that we can only ask questions answerable with standard methods. In a healthy science, research questions are chosen first and methods selected that can provide answers to them… even if those methods don’t look like what most others in the discipline are using.
Look, ALL types of measurement perform well in some conditions and poorly in others (true even of automated lab systems!). The key is knowing which condition is which, so you can set up your chosen measurement system to yield good data. That’s no more or less true, or controversial, for verbal-report measurement than for any other kind (you can survey some core issues defining trustworthy verbal report measurement in a chapter downloadable here). What separates verbal-report measurement and measurement based on direct observation is not some universal principle, but rather the fact that behavior analysts have spent a lot of time developing the latter (which they’re now very good at) while avoiding the former (about which they know close to nothing).
But back to the Byrne (2025) study with which I led this post. I’m all for finding better ways to teach novices! Let’s just not forget our own roles as lifelong learners who could benefit from occasionally re-examining the canon of behavioral research methods. I will never criticize an experiment that hews closely to the Sidman model or one of the variants that has been developed for applied research. But I would sure like to see more methodological creativity, and more appreciation of people like Byrne who demonstrate it.
Postscript 1: Alternatives to “Rat Lab”
Teaching labs are so valuable, and so effective in generating excitement for the objective understanding of behavior dynamics, that behavior analysts have done their best not to take the demise of “rat lab” lying down. Alternatives that have been commonly explored include classroom demonstrations involving students as “subjects” and simulations of behavior change in virtual environments. The classic example of classroom demonstration is the “shaping game” that is familiar to just about every teacher of behavior principles (download here for additional examples). One of the early virtual substitutes was “Sniffy the Rat,” which in its early form my students found neither convincing nor interesting, but perhaps more recent simulation programs are better. One that’s getting a lot of buzz is the Portable Operant Teaching Lab (e.g., here and here). I’ve not used it but my partner in ABAI blogging crime, Mirari Elcoro, has written about her experiences with it (here and here). Finally, some creative individuals have found ways to take “Rat Lab” our of the classroom by having students do behavior change in applied settings such as zoos. My former colleague at Illinois State University, Valeri Farmer-Dougan, opened a clinic that specialized in training shelter dogs (many visually or hearing impaired) to be more adoptable. Students served as “therapists” (trainers). “Dog Lab” was incredibly popular. Community dog rescue agencies adored it. Among students it was the most in-demand class in my department, and graduating seniors often listed it as their best experience at the university. Originally the clinic was held on campus but the university, in its inimitable wisdom, cannibalized the space for more mundane uses. Val was creative and worked out an arrangement with a rescue agency to hold “Dog Lab” there, and students were willing to drive a considerable distance off campus just to have the experience. But this instance illustrates another reason why teaching labs have gone by the wayside: Labs tend to require dedicated space, and at universities space is gold. Unfortunately behavior analysts rarely have the clout to stake an enduring claim to it.
Postscript 2: Different Missions
Point of clarification: Skinner’s early schedules experiments and Sidmanesque steady-state designs and are different largely because the serve different purposes. Skinner took behavioral snapshots of a given contingency arrangement or transition between contingency arrangements. Sidman showed us how to minimize threats to internal validity in comparisons between different contingency arrangements — at whatever time/effort cost. Byrne (2025), and this post, focus on making research less of a time suck.
Postscript 3: The Curious Exception to Our Discipline’s Aversion to Verbal Report Data
I can’t really explain this, but despite all of the resistance to verbal report measurement, somehow applied behavior analysis have embraced what Wolf (1978) called social validity measurement — basically customer satisfaction data in which you ask clients if they are happy with an intervention. There are good practical reasons to do social validity measurement, but there are good practical reasons to do all sorts of things that behavior analysts despise. Wolf felt so squeamish about violate the “behavior only” clause of the methodological orthodoxy that the first words of his article are, and I am not making this up, “I apologize.”
Unfortunately, social validity an exception that proves the rule that we don’t always think deeply enough about our methodological traditions. Behavior analysts adopted social validity measurement without ever identifying good methodological reasons for doing so. That adoption influenced little else in behavioral research, which may be a good thing since most social validity measurement isn’t very methodologically sophisticated. There are best practices of verbal behavior measurement, and social validity practices in behavior analysis respect basically none of them. If there’s a moral, I guess it would be: Yes, let’s innovate methodologically, but let’s be good methodologists in the process.
Postscript 4: How I Obtained Passable Stimulus Generalization Gradients in About Two Minutes
In my pilot study, the stimuli were white triangles in which a percentage of the area was shaded green (examples below). Note that this was nominal percentage as determined by a graphics program; I’m not sure the percentages pass the eyeball test for accuracy, but they do represent a clear ordinal gradation).

S+ was the 50% shaded triangle, with two S- stimuli being the 30% and 70% shapes. In the first trial of a three-trial orientation, participants were shown S+ and told, “Here is a shape for you to learn about. When you see this shape, respond with VEK.“ On the remaining trials an S- was shown and participants were told, “This is NUP. What is not VEK is NUP. When you see this shape, respond with NUP.“ Across 18 training trials the S+ and S- stimuli were presented an equal number of times, with VEK and NUP as response options. All participants scored 100% correct.
Generalization testing presented 17 gradations of green fill (ranging from 10% to 90% in increments of 5%). The rating-scale generalization test was completed once per condition or group. Prior to the first trial on-screen instructions stated: “You just learned about some shapes. Please rate how CONFIDENT you are about some shape judgments.” Each item asked, “Is this VEK?” and presented the response scale of “1 = very sure this is not VEK, 90= very sure this is VEK.” Participants typed in a numerical rating. Across 17 trials, each test stimulus was shown once, in randomized order, allowing for a complete generalization gradient.
That procedure was replicated four times per participant, yielding these results. For 3 of 4 participants, the gradients look a lot like what you’d expect. They are a bit messy, but individual generalization gradients often are (in fact, those tidy gradients you see in textbooks often are the aggregated data of several individuals).
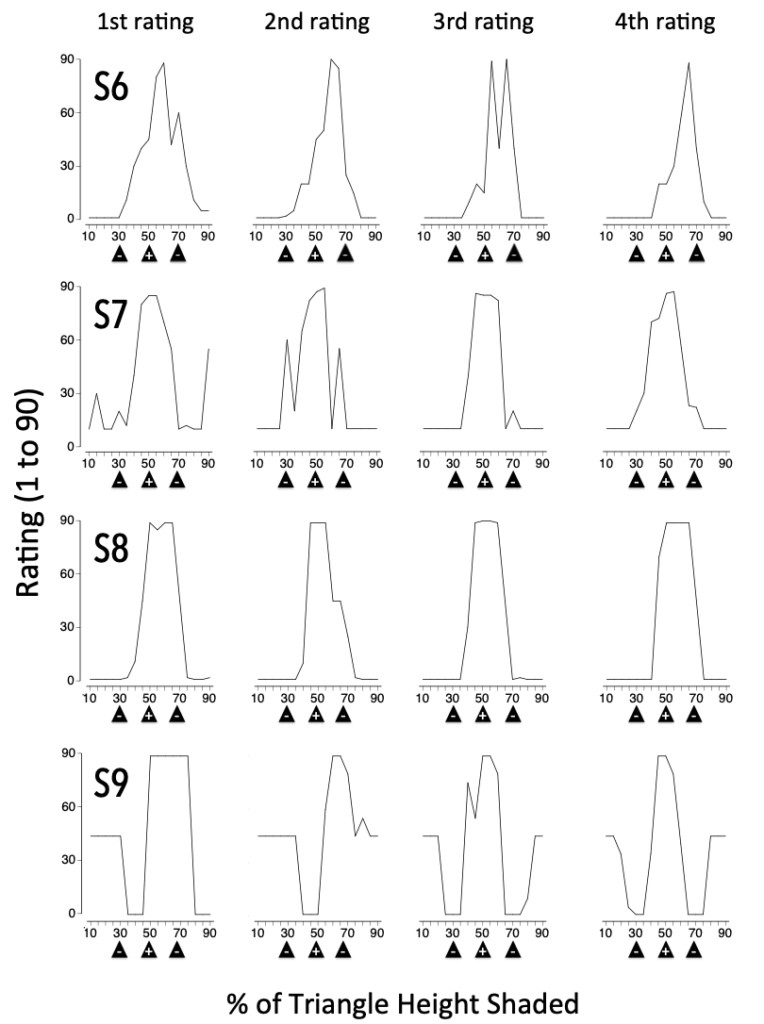
For those same individuals, what happened on Generalization Test 1 looks a lot like what happened on the subsequent tests. In other words, those verbal-report ratings were pretty reliable.
About Participant S9, well, many operant experiments yield an oddball participant. Stimulus control was pretty shaky during Tests 1 and 2, but by the third test S9 seemed to have settled into a pattern in which, at the least, S+ was rated confidently was VEK and the S- stimuli were rated confidently as NUP. So, in broad strokes this procedure, which took only a couple of minutes in total, yielded results much like you see in more involved traditional experiments.
The same procedure showed some of the classic effects seen in generalization gradients, such as peak shift, in which, following training with S+ and a single S-, the gradient is shifted away from S-.
In this case S+ was the 60% stimulus and S- was the 75% stimulus. Two generalization gradients were compared: the first (thin lines) after nondifferential orientation and training with S+ only and the second (thick lines) after differential orientation and training involving both S+ and S-.
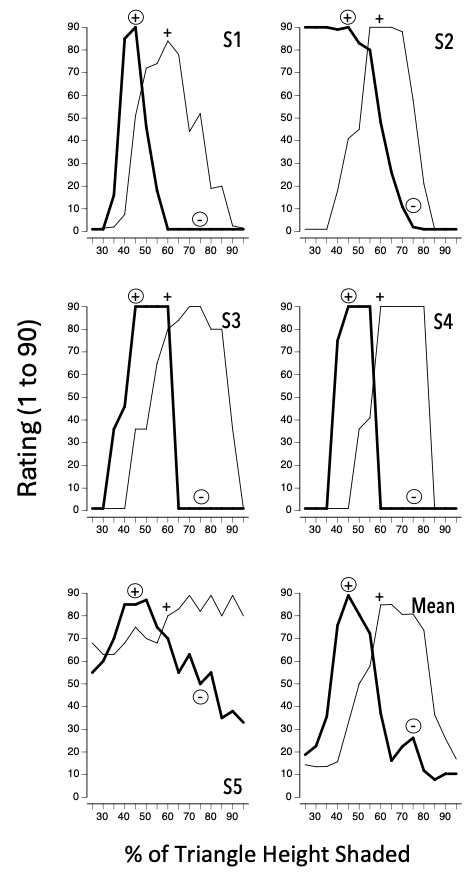
Again, there’s one clunker participant (S5), who showed no obvious stimulus control after differential training (note, however, that weak control following nondifferential training isn’t rare in the literature). Otherwise, the gradients obtained after nondifferential training were fairly symmetrical, as shown in the published literature. All participants showed a classic peak shift, in this case indicating that a stimulus to the left of the actual S+ (less green shading) was the one rated as “most like S+.”
Getting decent generalization data in less time seems like a goal worth pursuing, and there’s evidence that the goal is achievable. This is true for all of the reasons mentioned at the outset of this post, and especially so in protocols that are so complicated that it’s hard to fit everything in. Think of experiments that compare generalization gradients by the same participants under different conditions; or multimethod studies in which generalization testing is but one of a host of different kinds of measurement.
THEME MUSIC A: About Time
THEME MUSIC B: About The Necessity of Changing With the Times